[Lecture] Deploying Machine Learning Models in Production Week2 - 5. Batch Inference Scenarios, 6. Batch Processing with ETL
Batch Inference Scenarios
이번에는 Online inference가 아닌 Batch Inference에서의 model performance와 resoure requirements에 대해서 알아보았다.
Batch Inference는
그리고,
Batch Inference의 장/단점
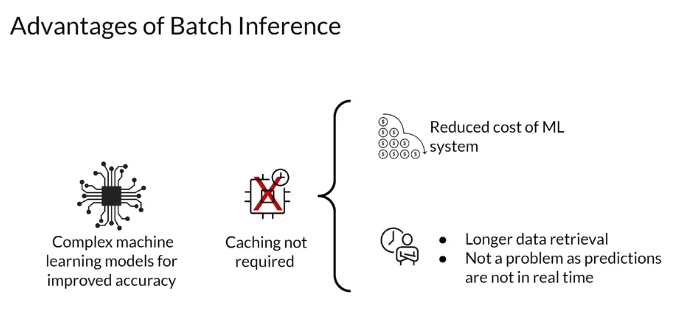
장점
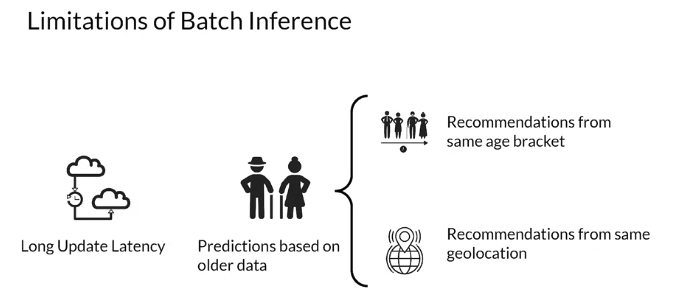
단점
Batch Inference가 사용되는 몇 가지 use cases를 살펴보자.
1. batch Inference을 하는데 optimize해야 할 가장 중요한 사항은 throughput이다. latency보다는 많은 양의 data를 한 번 batch prediction할 때 process할 수 있도록 throughput을 늘리는데 중점을 두어야 한다.
물론 throughput을 늘리려면 latency도 늘겠지만, batch Inference방식을 사용하는 경우에는 보통 바로바로 예측 결과가 바로바로 필요한 것이 아니기때문에 latency는 그렇게 큰 이슈가 되지 않는다.


Batch Inference Use-case
1.

2.

3.

6. Batch Processing with ETL
Data의 종류
| Batch processing | Stream processing | |
| Data scope | Queries or processing over all or most of the data in the dataset. | Queries or processing over data within a rolling time window, or on just the most recent data record. |
| Data size | Large batches of data. |
Individual records or micro batches consisting of a few records. |
| Performance | Latencies in minutes to hours. | Requires latency in the order of seconds or milliseconds. |
| Analysis | Complex analytics. | Simple response functions, aggregates, and rolling metrics. |
ETL이란? ETL ( Extraction, Transformation, Loading)
Batch Prediction을 하기 위해서는
- log file, csv file 에 있는 batch data, streaming data 또는 API형태일 수도 있고.. 이렇게 data의 source가 되는 곳에서 data를 Extraction한다.
- 그리고 활용 할 수 있는 형태로 Transform한다.
- DB나 Data mart, Data Warehouse.. 등에 Load 한다.
data를 Load하는 곳을 Data lake에 한다는 설명도 있고, Data mart, Data warehouse.. 다양한 설명이 있었다.
이 각각이 뭐고, 차이점이 뭔지 알아봐야 겠다. (Data Warehouse vs Data Mart: What is the Difference?. [개념정리]-Data Mart, Data Warehouse, Data Lake )
출처: https://ehyun0128.github.io/miscellaneous/dm_dw_dl/
그리고 이 과정을 Pipeline으로 만들어서 과정을 실행시킬 수 있도록 한 것이 ETL pipeline이 된다.
또한 ETL pipeline을 거쳐서 사용가능하게 준비된 데이터들은 꼭 prediction말고도 training, 다양한 analytics, data mining, ...등에
정리하면, ETL이란 데이터 웨어하우스 구축 시 데이터를 운영 시스템에서 추출(Extraction)하여 가공(Transformation) 한 후, 데이터 웨어하우스에 적재(Loading)하는 모든 과정을 말한다.

어떤 과정인지 예를 들어보면,
어떤 소매점에 영업, 마케팅, 물류 부서가 있다. 각 부서마다 고객 정보를 독립적으로 처리하기 때문에 데이터를 저장하는 방식이 통일되어있지 않다. 영업 부서는 고객을 이름으로 저장하고, 마케팅 부서는 ID로 저장하는 등이다.
이런 상황에서 누군가 '고객의 이력을 확인하고 어떤 마케팅 캠페인으로부터 어떤 물건을 구매했는지 알고 싶다'면 매우 비효율적이게 된다.
이럴 때 ETL은 서로 다른 데이터세트 들을 통합된 구조에 맞게 변환해주는 점을 사용하여 데이터 웨어하우스에서 ETL을 사용하여서 각각의 정보를 저장한다면 데이터에서 의미있는 분석을 할 수 있을 것이다.

ETL의 Distributed Processing
많은 양의 데이터를 ETL처리 해줄 때는 분산 처리 방식으로 하는 것이 좋다.
데이터들이 여러 workers로 나뉘어 parallely 하게 이 작업이 수행되는 것이다.

ETL Pipeline components
1) For Batch Processing

2) For Stream Processing
Sensor같이 계속해서 데이터가 생성되는 경우, 해당 Sensor에 Kafka나 Google Cloud의 Pub/Sub을 연결하면 되고, ETL과정은 Batch Processing과 같이 Cloud DataFlow와 Apache Beam의 조합으로 가능하다.
그리고 Spark중에서는 특히 Stream data를 Processing하기 위한 서비스가 있고, Kafka로도 Stream data의 ETL 작업을 진행 할 수있다.
