[MSA, Monitoring] Kubernetes Monitoring with Prometheus, Grafana
관련 코드는 https://github.com/Gracechung-sw/kubernetes-practice/tree/main/k8s-monitoring 에서 확인하실 수 있습니다.
1. Kubernetes monitoring
1) node - application 의 관계: 1:1 -> 1:N
node와 application의 관계가 더이상 1:1 이 아니라 node에는 많은 application이 scheduling될 수 있다. 그래서
- 무엇을 모니터링 해야하는지 설정할 수 있어야 하고,
- 모니터링 시스템이 자동으로 감지하고 metric을 수집할 수 있도록 pull-based 모니터링이 사용되고 있다.
2) push-based monitoring vs pull-based monitoring
- Push-based monitoring: Metrics are defined centrally and PUSHED out to assigned hosts and agents.
- pros) node에 변경이 생겼을 때 node agent가 바로 monitoring system에 알릴 수 있다는 것
- cons) node수가 많아지면 monitoring system에 전달되는 정보에 대한 조절이 불가하고, 한번에 몰릴 수 있음
- Pull-based monitoring: The agents somehow know what they need to collect and push the metrics (and often any metadata like units, plus tags) to the central system. From the central monitoring system it’s getting, or pulling, the configs & metric metadata, from the agents.
- pros) 모니터링 대상에 대한 동적 대응 가능.
2. Monitoring targets
쿠버네티스에서 모니터링 해야 할 대상엔 아래의 것들이 있다.
1) Kubernetes cluster
노드의 리소스를 모두 사용하면 그 노드 내 실행되고 있던 Pod가 Crush되고, 다른 node로 scheduling되는데 이런 것들 때문이라도 node의 리소스를 항상 파악하고 있어야 함. 그리고 node의 리소스 가용량도 계속 파악하고 있어야 다른 Pod실행 가능성을 알 수 있음.
- Kubernetes component monitoring
- Kubernetes node monitoring
- Cluster API request time
2) Kubernetes pod
Pod status(Healthy / Unhealthy)는 Pod가 계속 running 중인지, 재시작되는 pod가 있는지 or 재시작되는 이유가 자원이 부족해서인지 application 내부에서 crush등이 되어서인지. 그리고 Pod resource usage 를 알아야 node의 memory와 pod의 memory 사용량을 계속 비교하면서 초과시 pod를 다른 node로 이동한다거나 pod를 재시작 할 수 있다.
- Pod status(Healthy / Unhealthy)
- Pod resource usage (CPU, Memory, Disk, …)
-> Metric
- system metric
- service metric
이러한 쿠버네티스 모니터링 수집 지표를 metric이라고 하고
metric의 종류에는 k8s 중 node나 컴포넌트가 사용하는 자원의 지표를 system metric,
클러스터에 생성된 pod의 지표를 service metric이라고 한다.
3. Tools for Monitoring Resources
1) Core metric pipeline (Resource Metric Pipeline)
- metric server에 의해 제공되는 node, pod 모니터링
- node와 pod의 CPU, Memory 사용량을 제공
- HPA 등의 auto scale기능에서 활용 그리고 사용자는 kubectl top명령어를 통해 사용량을 제공받을 수 있음.

2) Monitoring pipeline (Full Metric Pipeline)
- 리소스 메트릭 이상의 정보가 필요한 경우
- 다양한 metric을 추가 가능
- 리소스 메트릭 + many custom metric

- Paid monitoring tool: Datadog, Newrelic, Dynatrace
- Open source project: Prometheus, Grafana
상용 모니터링 툴은 비용을 지불함으로써 쉬운 설치, 풍부한 기능, 기술 지원 등이 가능
하지만 보통 prometheus, grafana 조합을 많이 사용.
prometheus는 k8s의 모든 자원을 모니터링 할 수 있고, 알람 기능이 있어서 장애를 사전에 대비, 빠른 대응 가능
Grafana는 prometheus에서 제공하는 Metric을 잘 가공해서 이를 다양한 형식의 graph dashboard로 보여주는 project이다.
4. Prometheus
Prometheus is one of the most popular open-source tools used to monitor Kubernetes. It was developed by SoundCloud and donated to the CNCF (Cloud Native Computing Foundation).
What’s different about Prometheus compared to other time-series databases – such as Cassandra, Graphite, InfluxDB – is that it has a simple yet powerful multidimensional data model and its flexible query language (PromQL). Furthermore, it follows a pull model rather than push and has built-in real-time alerting mechanisms. Finally, being open-source, it gathered a large community interested in helping and bringing innovation.
You can easily run Prometheus on top of Kubernetes by using the Prometheus Operator.
Pros:
- Built-in monitoring and alerting
- Functional and reliable during outages
- Kubernetes-native, easy to use
- Integrates well with Grafana
- Large community
Cons:
- No built-in long-term storage
- No authentication/authorization
- No anomaly detection
- Doesn’t handle logs or traces, only metrics
- Challenges at scale
Soundcloud에서 개발하고 CNCF에서 지원하는 오픈소스 모니터링 솔루션이며
일정 시간마다 타겟으로부터 메트릭을 수집하고 이 조건에 따라 수집된 메트릭을 가공할 수 있는 쿼리(PromQL)을 제공한다.
그리고 조건에 따른 알람을 발생시키기도 함.
프로메테우스의 특징이자 장점이라고 할 수 있는 것은
- 단일 메트릭에 여러 조건을 더해서 새로운 data를 재생성 할 수 있는 multi dimensional data model이며
- PromQL이라는 쿼리 랭귀지를 제공해서 수집된 메트릭을 조회 가능
- 저장시 분산 스토리지를 지원
- pull based 모니터링
Prometheus Architecture
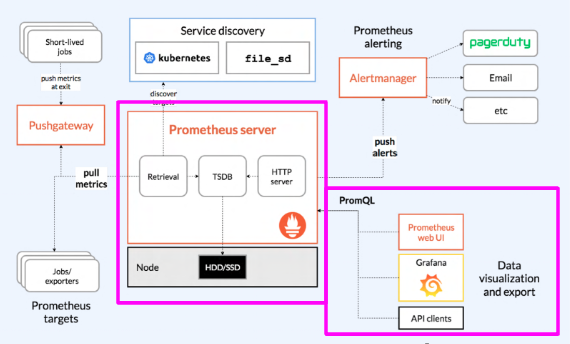
- Data Retrieval component: Retrieval이라고 하는 데이터 수신 component가 metric을 받아온다 그리고 k8s의 모든 node, service, application에 대한 metric을 TSDB에 저장
- TSDB(Time Series Database): metric 데이터를 발생한 시간별로 저장한다.
- HTTP server: 이렇게 저장된 metric데이터는 HTTP server를 통해 외부에서 접근 가능.
사용자는 Prometheus web UI를 통해 직접 PromQL 쿼리로 요청 할 수도 있고, Grafana같은 외부 프로젝트에서 쿼리를 통해 가져온 것을 시각화 할 수도 있다.
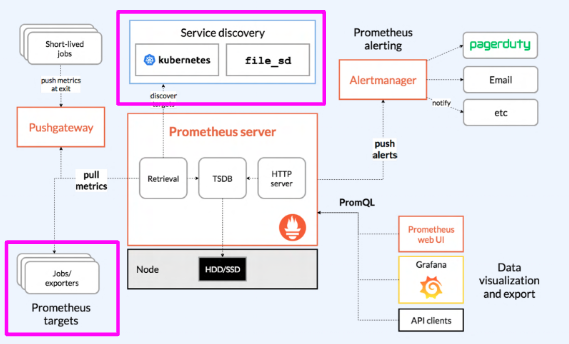
- 모니터링 하는 타겟으로 부터 pull
- 이 타겟은 서비스 디스커버리를 통해서 모니터할 대상을 설정한 것을 자동 타겟 설정
- 이 service discovery에는 어떤 target을 모니터링 할 지 파일로 정의한 file_sd가 있다.
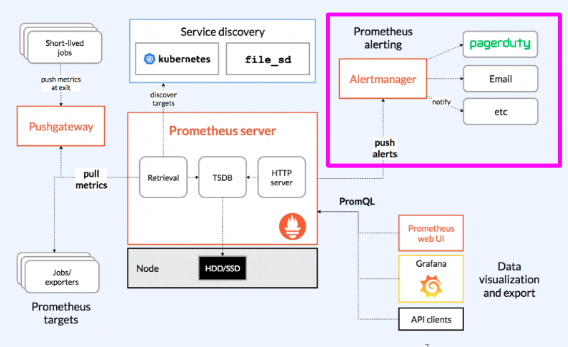
- Prometheus의 알람 전송
- 다양한 전송 수단 지원
- 조건별 전송
5. Grafana

- 데이터 시각화
- 용도별 대시보드 사용
- 자유로운 그래프 배치
6. Production level kubernetes monitoring using Prometheus - Grafana - Slack alert
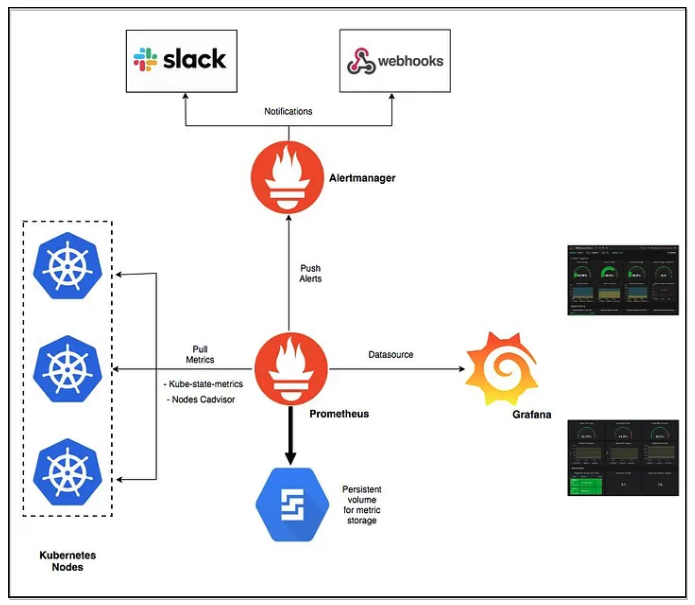
minikube 환경에서 실행
1) K8s cluster에 metrics server 설치
# metrics server yaml file을 download
$ wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 위 명령어로 다운받은 components.yaml 에 명시되어있는 K8s object들을 설치
$ kubectl apply -f ./components.yaml
# metrics server 설치 확인
$ kubectl get po -n kube-system2) metric api를 사용해서 node와 pod의 사용량 metrics을 확인
# ( metric api x) 그냥 top 명령어 사용
$ kubectl top node
$ kubectl top pod -n kube-system
# 이러면 NAME CPU(cors) MEMORY(bytes) 정보들이 나옴.이 service들은 web UI를 제공하고 있기 때문에 외부에서도 접근 가능해야하는데, 보이는 것 처럼 EXTERNAL-IP가 none이다. port forwarding을 사용할 수도 있지만, Load balancer를 사용해서 외부에서 접근 가능하도록 설정할 것임
3) Prometheus와 Grafana를 통한 k8s 모니터링 - 설치
# 쿠버네티스 클러스터 환경에서 사용할 수 있도록 clone해온 뒤 menifest들을 설치한다.
git clone https://github.com/prometheus-operator/kube-prometheus.git -b release-0.10
kubectl create -f ./manifests/setup/
kubectl create -f ./manifests/
# 설치된 pod 확인
kubectl -n monitoring get pods
# 설치된 service들 확인
kubectl get svc -n monitoring
EXTERNAL-IP 잘 할당 받는 것을 알 수 있다.
- Prometeus, grafana ui 접근
- Prometeus ui에 들어가 어떤 기능을 제공하는지 봐보자.
- grafana ui 접근하면, 기본적으로 prometheus에서 제공해주는 메트릭으로 이루어진 기본 dashboard를 제공함.
Reference
overall:
Kubernetes와 Docker로 한 번에 끝내는 컨테이너 기반 MSA
1. Kubernetes monitoring
https://steve-mushero.medium.com/push-vs-pull-configs-for-monitoring-c541eaf9e927
3.Tools for Monitoring Resources
https://kubernetes.io/docs/tasks/debug/debug-cluster/resource-usage-monitoring/
https://kubernetes.io/docs/tasks/debug/debug-cluster/resource-metrics-pipeline/
13 Best Kubernetes Monitoring Tools: Free, Open Source & Paid [2023 Comparison]
6. Production level kubernetes monitoring using Prometheus - Grafana - Slack alert
https://medium.com/faun/production-grade-kubernetes-monitoring-using-prometheus-78144b835b60