대세는 쿠버네티스 강의와 Kubernetes와 Docker로 한 번에 끝내는 컨테이너 기반 MSA를 참고하여
공부한 바를 정리하였습니다.
1. 쿠버네티스 공부를 시작하는 이유

내가 해온 일 들 중 서비스 운영에 대해 고민했던 시기들을 그려본 것이다.
Docker를 이용한 서비스 배포 과정에 CI/CD와 service alert 기능을 추가한 이후에도, 여러 서버에 container를 효과적으로 모니터링하고 관리하는데 어려움이 있었다.
예를 들면, 서버 health check는 정상이지만 그 안에 container가 지속적으로 down되는 문제가 발생했을 때 이를 알아차리기란 쉽지 않다. 그리고 많은 연산에 리소스가 들어가는 서비스의 경우 리소스를 효율적으로 관리하고 분배하도록 인프라를 직접 관리하는 것도 부담으로 다가온다.
또한 scalable 한 서비스를 위해 scaler를 설계하고 구현해야 하는 필요성이 생기는데, Cloud 서비스 내의 Auto scaling 기능을 사용하면 반응 시간이나 edge case등에 빠르게 scale out되기 어렵다.
물론 이러한 문제들을 잘 핸들링 할 수 있는 시스템을 설계하고, scaler policy를 정해서 직접 개발, 관리할 수도 있겠지만 kubernetes가 이런 문제를 어느 정도 해결해 줄 수 있고, 사용 전/후의 차이가 어느 정도일지 가늠해보기 위해서 공부를 시작했다.
2. 가상화 기술 히스토리와 쿠버네티스
큰 기업들은 대규모의 서비스를 운영하고 있기 때문에 최대한 자원을 효율적으로 써야 비용적으로 유리하다.
그래서 서버 자원을 효율적으로 쓰기 위해서는 가상화기술에 대해 관심을 가질 수 밖에 없는데, 쿠버네티스를 좀 더 잘 이해하려면 가상화기술들에 대한 히스토리를 알 필요가 있다.
Linux의 자원격리기술 → VM(가상화기술) → 그런데 하다보니 자동화는 되는 거 같은데 생각보다 시스템 효율이 나질 않음. 왜?
→ 가장 큰 원인이 VM 가상화를 하기 위해서는 무거운 OS를 띄어야 한다는 점이다. 그래서 가벼운 서비스를 하나 띄우기 위해 이것 보다 더 무거운 OS를 띄워야 하는 경우가 생기는 것임
→ 자원격리기술을 Container라는 개념으로 누구나 사용하기 쉽게하는 가상화기술이 나왔고 Docker라는 이름의 오픈소스로 공개
→ 컨테이너 가상화기술은 서비스간에 자원을 격리하는데 OS를 별도로 띄우지 않아도 되고, OS 가동시간이 없기 때문에 자동화시 빠르고 효율도 높다.
→ 하지만 Docker는 하나의 서비스를 컨테이너로 가상화시켜서 배포하는데 도움을 주는 것이지, 많은 서비스를 운영 할 때, 일일이 배포, 운영하는 역할을 해주지는 않는다.
→ 이렇게 여러 컨테이너를 관리해주는 솔루션 역할을 해주는 '컨테이너 오케스트레이터'로 가장 많이 사용되고 있고, 만족도가 높은 오케스트레이터가 쿠버네티스이다.
→ 이 쿠버네티스가 표준이 되어감에 따라 많은 클라우드서비스들이 쿠버네티스 환경이 설치되어있는 인프라를 서비스하고 있다.
3. 쿠버네티스의 필요성
위에서 언급한 서비스 운영, scaling 측면에서 미리 트래픽을 예측하기도 쉽지 않고, 미리 자원을 넉넉하게 준비해두는 것도 비용적인 측면에서 쉽지 않다. 또한 여러 서비스를 운영할 때라면 더더욱 이런 부분을 핸들링 하기 어렵다.
※ 한 서버에 한 서비스를 배포해서 사용할 때의 문제점을 살펴보고 이 경우 발생할 수 있는 문제들을 쿠버네티스로 어떻게 해결할 수 있는지 배워보자.
해당 문제는 실무에서 내가 고민해봐야할 가장 큰 주제 중 하나이며, 해당 강의를 듣고 공부하면서 계속 상기시켜봐야할 질문 주제이다.

한 회사에서 3개의 서비스를 운영하고 있다고 치자.
- 아침에는 A 서비스의 이용이 많고, 3대의 자원이 필요
- 정오에는 B 서비스, 3대의 자원이 필요
- 밤에는 C 서비스, 3대의 자원이 필요
- 각 각 서비스당 3개의 서버 즉, 9개의 서버가 계속 켜져있고,
- 추가로 장애 대비 백업서버까지 상시 준비되어있어야 하므로 비효율적이다.
여기서 kubernetes기술을 사용한다면
- 평균 4개의 서버만 준비하고, kubernetes의 auto scaling 기능을 사용해서 traffic의 양에 따라 자원 양을 변경시켜 주면서 서비스해준다.
- 그리고 장애가 발생했을 때 필요한 백업서버 같은 경우에도, kubernetes에는 다른 서버로 장애가 난 서버가 수행하던 것을 자동으로 옮겨주는 auto healing 기능을 사용할 수 있다.
- 그리고 무중단 배포를 지원하는 기능도 있음.
이런 운영 적인 측면 이외에도,
시스템 개발 사상적인 측면의 변화에도 쿠버네티스의 역할이 정말 중요하다.

일반적으로 이전(Virtual Machine 환경에서의 개발)에는 한 언어를 사용해서 개발된 여러 모듈이 한 서비스에서 돌아가도록 개발되었다.
만약 한 서비스의 VM에 Java로 개발된 Module A, B, C가 있다고 하자. 이때 A 모듈에만 부하가 많이 발생하더라도 새로운 VM을 띄워 A, B, C모두 추가가 되어야 한다. 즉, 자원 사용이 효율적으로 되었다고 할 수 없다.
반면 MicroService 형식으로 한 서비스를 만들 때 모듈별로 가장 적합한 언어로 각각 개발될 수 있고, 각각 container에서 실행되도록 할 수 있다.
여기서 kubernetes가 1개 이상 container를 한 pod로 묶어서 배포 단위로 삼을 수 있다. 이렇게 되면 필요한 pod만 늘릴 수 있는 것이다.
4. 쿠버네티스의 의미
쿠버네티스는 여러 개의 컨테이너화된 애플리케이션을 여러 서버(쿠버네티스 클러스터)에 자동으로 배포, 스케일링 및 관리해주는 오픈소스 시스템이다.
- 쿠버네티스(조타수) : 주어진 명령을 핸들에 반복 실행해야 한다.

- 쿠버네티스에 애플리케이션을 배포한다란,
- 애플리케이션을 배포하기위한 script(즉, 쿠버네티스 오브젝트 Manifest 파일)를 쿠버네티스가 알 수 있는 형식으로 적어서(표현 방식: YAML형식) Master node API Server에 전달(전달 방식: Rest API)하는 작업이다.
- 쿠버네티스 오브젝트란,
- 개발자/운영자의 '쿠버네티스 클러스터에 어떤 애플리케이션(Pod)을 얼마나(ReplicaSet) 어디에(Node, Namespace) 어떤 방식으로 배포할 것인가(Deployment). 그리고 운영할 것인가(Service, Endpoints...)'라는 리소스 의도를 정의하는 방법이다.
- ※ () 안에 적은 쿠버네티스 오브젝트 상태들을 아래 <5. 쿠버네티스의 구성>에 정리해두었다.
- Manifest 파일이란,
- 쿠버네티스 오브젝트를 생성하기 위한 필수 정보들이 적혀있는 쿠버네티스에 일을 시키기 위한 지시서.
- 오브젝트 기본 정보(필수값) Manifest 파일 예시
apiVersion: apps/v1 # 오브젝트를 생성할 때 사용하는 API 버전
kind: Deployment # 생성하고자 하는 오브젝트 종류
metadata: # 오브젝트를 구분 지을 수 있는 정보
# name, resourceVersion, labels, namespace, ... 등이 있을 수 있다.
name: nginx-deployment
spec: # 사용자가 원하는 오브젝트 상태 (속성은 오브젝트 종류마다 다르기 때문에 https://kubernetes.io/docs/reference/kubernetes-api/ 참고)
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
resources:
limits:
memory: "64Mi"
cpu: "50m"5. 쿠버네티스의 구성
0) Cluster
: cluster는 여러 개의 서버를 하나로 묶어서 하나의 서버처럼 동작하게끔 만들어 둔 것으로 kubernetes cluster는 애플리케이션 컨테이너들을 쿠버네티스가 관리하기 위한 서버 집합으로 볼 수 있다.
1) Master & node server
: Cluster에는 master node 서버 한 대. 나머지는 worker node로 구성되어 있다.
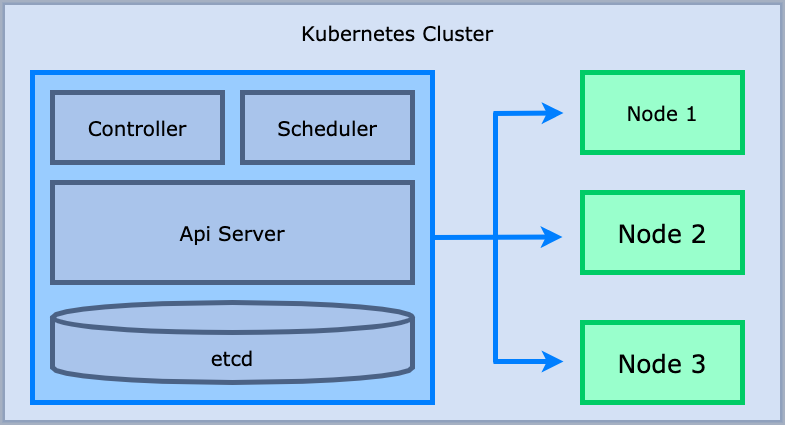
Master node의 구성요소
- Api server: 쿠버네티스의 모든 요청(ex. 클러스터 상태 조회, 변경)들이 이를 통해 수행
- etcd(key-value data store): 쿠버네티스 클러스터의 모든 상태, 클러스터에 배포된 애플리케이션 실행 정보 저장
- controller: Desired state를 유지하기 위해 변경사항 지속 모니터링, 만약 desired state를 만족하지 않는다면 api server에 요청
- scheduler: 어느 node에 띄울 것인지 node scheduling 결정
Worker node의 구성요소
- container runtime Docker
- pod: 하나 또는 그 이상의 애플리케이션 컨테이너 (도커와 같은)들의 그룹을 나타내는 쿠버네티스의 추상적 개념
- 하나의 독립적인 서비스를 구동할 수 있는 컨테이너들이 있다.
- pod는 node 내에서 구동
- Kubelet
- Kubelet은 파드에서 컨테이너가 확실하게 동작하도록 관리합니다.
- Kube-Proxy
- 노드로 들어오거는 네트워크 트래픽을 적절한 컨테이너로 라우팅하고, 로드밸런싱등 노드로 들어오고 나가는 네트워크 트래픽을 프록시하고, 노드와 마스터간의 네트워크 통신을 관리
- pod: 하나 또는 그 이상의 애플리케이션 컨테이너 (도커와 같은)들의 그룹을 나타내는 쿠버네티스의 추상적 개념

2) Namespace:
cluster내의 namespace가 kubernetes의 object들을 독립된 공간으로 분리될 수 있게 해준다.
3) Pod:
namespace에는 kubernetes의 최소 배포 단위인 pod들이 있다.
4) Service:
이 Pod들에게 외부로부터 접근이 가능하도록 IP를 제공해준다.
5) container:
pod들에는 1개 이상의 container가 존재하고, 이 container들에서 하나의 앱들이 실행 중임. 그래서 pod에는 여러 앱들이 실행 중일 수 있는 것이다.
6) volume:
pod가 재생성되어도 데이터가 유지 될 수 있도록
7) ResourceQuota/LimitRange:
Pod 설정의 resource 부분을 보면 Request와 Limit가 존재하는 것을 알 수 있습니다.Pod는 기본적으로 Memory를 500Mb 사용을 보장하되 더 많은 Memory를 필요로 할 경우에는 최대 750Mb까지 사용할 수 있는 것을 나타냅니다.
정리해 보면 Request는 적어도 이 만큼의 자원은 컨테이너에게 보장돼야 한다는 것을 나타냅니다. Limit는 유휴 자원이 있다면 최대 이 만큼의 자원까지 컨테이너가 사용할 수 있다는 것을 나타냅니다.
8) ConfigMap/ Secret:
이 것들을 통해서 환경변수나 mount 정보 등 config에 관련된 것들을 관리
9) Controller:
pod들을 관리
- Replication Contoller, ReplicaSet: pod 개수 scale in/out 또는 죽은 pod 살리기
- Deployment: 배포 update or rollback
- DeamonSet
- CronJob
6. 쿠버네티스의 동작 방식

- 사용자는 kubectl로 쿠버네티스 클러스터와 통신
- 클러스터 내의 Master는 쿠버네티스의 설정 환경을 저장하고, 전체 클러스터를 관리
- 각 Node들에서는 쿠버네티스 위에서 동작하는 워크로드(pod)들이 실행
- 쿠버네티스는 기본적으로 내가 원하는 상태(Desired State)와 현재 상태(Current State)를 비교하고,
- 만약 원하는 상태와 현재 상태가 다르다면 현재 상태를 원하는 상태로 변경하는 기능을 수행한다.

- Python App을 띄우도록 하는 Yaml파일을 작성하여 kubectl를 이용하여 파이썬 애플리케이션 실행되도록 쿠버네티스 클러스터에 요청
- 우리가 보낸 요청은 Api Server가 받게 되고 etcd라는 key, value저장소에 어떤 상태가 되어야 하는지를 저장

- Controller는 etcd에 저장되어있는 내용을 지속적으로 확인
- 확인된 내용과 현재 상태가 다를 경우 위에서 설명한 Desired State를 유지하기 위한 조치

- Scheduler는 위의 Controller에서 새로운 워크로드(Pod)를 띄워야 한다고 했을 때 어떤 Node에 띄워야 하는지를 결정

7. Getting Started
시나리오:
- linux 서버에서 hello world 라는 nodejs 서버를 만들어서 띄워 볼 것.
- docker 설치 후 nodejs docker image를 가져와서 앞 단계에서 만든 hello world nodejs 서버 container를 실행 해 볼 것.
- kubernetes를 사용해서 hello world nodejs 서버 이미지를 가져와서 pod를 생성 및 pod를 통해 container 실행 해 볼 것.
- 또한 외부에서 접근 가능한 service를 만들어서 외부로 open 시켜볼 것
- 외부에서 service에 작성된 주소로 hello world nodejs 서버에 접근 가능한지 테스트.
1) hello world 라는 nodejs 서버를 만들어서 띄워본다.
hello.js 작성
var http = require('http');
var content = function(req, resp) {
resp.end("Hello Kubernetes!" + "\n");
resp.writeHead(200);
}
var w = http.createServer(content);
w.listen(8000);서버 실행
node hello.js
2) docker 설치 후 nodejs docker image를 가져와서 앞 단계에서 만든 hello world nodejs 서버 container를 실행 해 볼 것.
Dockerfile 작성
FROM node:slim
EXPOSE 8000
COPY hello.js .
CMD node hello.js
Docker image build & Docker Container Run
# dockerfile build
docker build -t kubetm/hello .
# -t : 레파지토리/이미지명:버전
# build 된 docker image 확인
docker images
# 실행
docker run -d -p 8100:8000 kubetm/hello
# -d : 백그라운드 모드
# -p : 포트변경
# 실행되고 있는 container 확인
docker ps
# 해당 container 환경으로 들어가보기
docker exec -it [container ID] /bin/bash3) kubernetes를 사용해서 hello world nodejs 서버 이미지를 가져와서 pod를 생성 및 pod를 통해 container를 실행한다.
apiVersion: v1
kind: Pod
metadata:
name: hello-pod
labels:
app: hello
spec:
containers:
- name: hello-container
image: kubetm/hello
ports:
- containerPort: 8000
4) 외부에서 접근 가능한 service를 만들어서 외부로 open 시킨다.
apiVersion: v1
kind: Service
metadata:
name: hello-svc
spec:
selector:
app: hello
ports:
- port: 8200
targetPort: 8000
externalIPs:
- 192.168.56.30