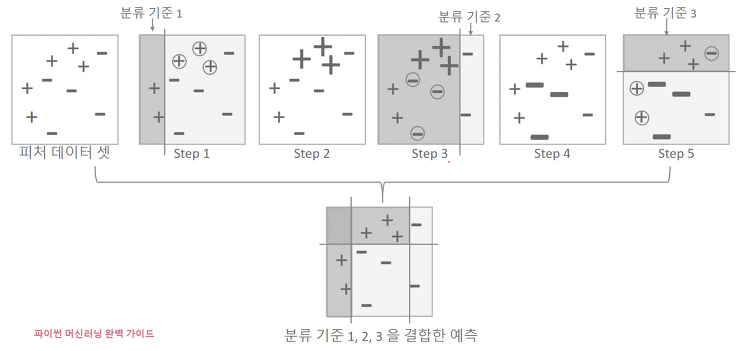
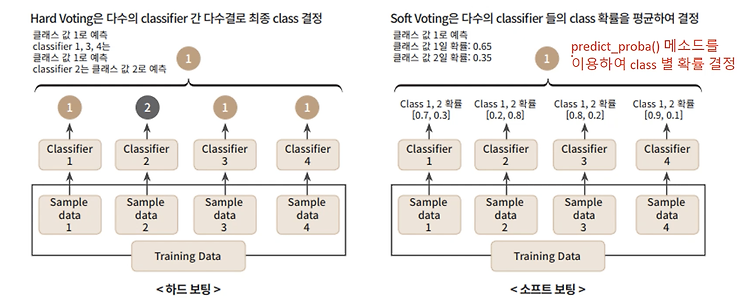
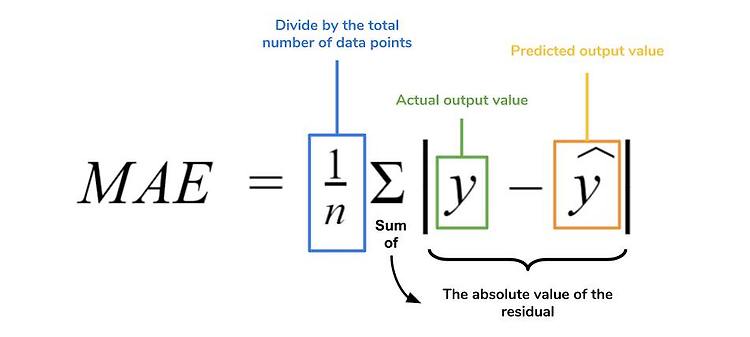
Regression2. 경사하강법 수행 프로세스와 python code
Gradient Descent¶ Y=4X+6이 실제값 일 때, y = 4X + 6 식을 근사(w1=4, w0=6)하고 noise가 있는 random 값을 데이터로 만들어서 최적의 회귀계수를 찾아가도록 해본다.¶ In [1]: import numpy as np import matplotlib.pyplot as plt %matplotlib inline np.random.seed(0) #.seed를 사용하면 실행 때 마다 동일한 셋트의 난수가 나타나게 할 수 있다. X = 2 * np.random.rand(100, 1) y = 6+4*X + np.random.randn(100, 1) #X, y 데이터셋을 scatter plot으로 시각화 print(X.shape, y.shape) plt.scatter(X, y..